

Congratulations! You’ve developed an NLP model that’s surpassed your target performance on the test dataset, even beating the crowdsourced human performance on a small subset of examples. Everyone is excited to move to production. But are you sure the model will serve the needs of all stakeholders once you hit “deploy”? In this first part of our series on Robustness in NLP, we will discuss subpopulation performance and how subset testing can guide you in shipping a quality language-enabled product.
What are Subpopulations?
NLP subpopulations represent subsets of the valid text data to be modeled. These can be defined in any number of ways. Some can be selected based on text features, such as the presence of certain words or phrases. Other subpopulations can be defined based on their domain. For instance, text taken from academic literature has different qualities to that written on social media platforms or the transcripts from customer support calls. Still other subpopulations can be defined using additional metadata captured during the collection process, such as the writer’s geographic location.
Comparing model behavior for salient subpopulations is a powerful tool in understanding how the model will be experienced by different users. It enables conditional analysis that can surface issues otherwise hidden in larger aggregate metrics.
You might be thinking, “Why the extra worry? My service is based on GPT-∞ and has compressed the sum total of internet knowledge. Isn’t that enough?”
Ignoring for the time-being that the training data is often low-quality and biased, containing, inter alia, stereotypes and pejorative language, low performance in itself can make your service inaccessible to many, risking alienation and harm. Even the largest models have failed to perform well in normal scenarios that were underrepresented in their training data because they are not optimized to model the physical world we live in. Though “foundational” models pre-trained on internet corpora have improved the generalizability of NLP, minimizing the average loss on heterogeneous data provides no guarantees on the performance for any specific domain or group of people.
Testing a model on salient, domain specific subpopulations that capture the variance in your data, therefore, is a powerful and important tool for identifying weaknesses before your model is put into production. Prioritizing performance on all key subpopulations not only improves robustness in known scenarios, it also can produce better performance on unseen or unanticipated subpopulations .
Case Study
Let’s say you wish to deploy a sentiment model into production. A common approach is to use a pretrained transformer encoder fine-tuned on in-domain sentiment data. You test the performance on a withheld split and on test sets from adjacent domains, selecting the model that performs adequately in terms of both accuracy and unweighted average recall. How do we verify that it behaves similarly for different users? Can subpopulation testing provide us with additional insights?
In this study, we will investigate the model behavior along a few simple dimensions: the presence of entity types, topics, gendered pronouns, perplexity, and readability. The data we are using comes from the English portion of WikiANN.
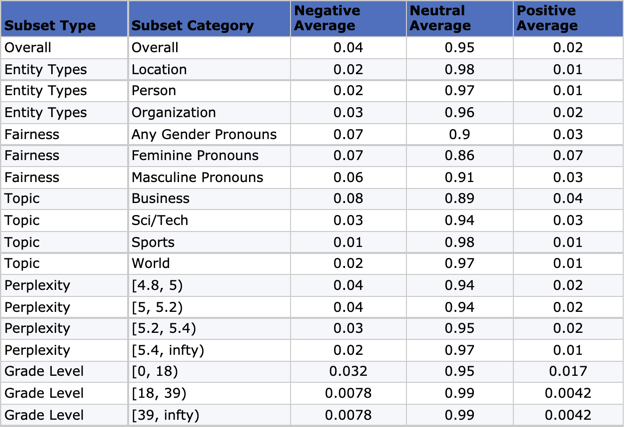
A few things stand out in the chart above. First, for the examples that contain entities of any selected type, the model tends to predict them as being more “neutral” than those without. Second, when looking at perplexity and grade level scores, the model assigns a higher weight to neutral sentiment for more complex or unexpected sentences than it does for simpler sentences. Third, the model predicts greater sentiment polarity for sentences classified as being related to “business” than for those dealing with topics like “sports” or “world”. Finally, for sentences containing gender-related pronouns, the neutral class is 5% less likely than in the overall dataset. Furthermore, the model predicts positive sentiment at twice the rate for sentences containing female pronouns as it does for those containing masculine ones.
Some of these results may surprise the model developer. For instance, she may have expected the language used in the sports and world topic subpopulation to be more sentiment-laden than that in the business and science subsets. Or she may have expected greater polarity for examples containing “person”-type entities, since these usually contain people’s names. To determine whether these discrepancies are encoded in the model, the data, or both, further analysis is required, which is why RIME employs several different methods in conjunction with subset testing to identify spurious correlations and bias, interpret model behavior, and secure your NLP model in production.
Conclusion
Even small, clean datasets like that used above contain a wide variety of subpopulations. Subset testing highlights how model predictions differ across subpopulations in ways that may not align with our intuitions. This helps catch bugs and vulnerabilities early on and clarifies how the model will generalize to new domains and how it behaves under concept drift. It is one tool we use at Robust Intelligence to synthesize a holistic and accurate view of your model and the data distribution it sees in production. In later posts, we will further investigate how to test shifts in the distribution of language and make your system more robust to these types of behavior.
[Appendix] How the subpopulations were selected
For this experiment, the “entity types” subsets were created using the provided dataset labels. If an entity of a certain type (i.e., organization, person, or location) was present anywhere in an example, that sentence was included in the target subset. The gender pronouns subsets were computed by looking for presence of any of the target pronouns within the set of whitespace-tokenized words of a given sentence. For instance, for the sentence “She passed him the ball.” The pronouns “she” and “him” are both present. This sentence would be included in all three of the masculine, feminine, and “any gender pronouns” subsets.
The remaining subsets were created by binning the scalar scores predicted by different off-the-shelf NLP models. The topic categories were inferred using a BERT model trained on the AG News corpus. The perplexity numbers were computed using the autoregressive language model GPT-2, and readability/grade level scores were assigned using the Flesch-Kincaid grade level formula.





