

There are several considerations one must take into account when moving a machine learning model from development into production. One of these, the topic of this blog post, is input validation.
Why Do We Care About Input Validation for Machine Learning?
During the prototyping phase, a data scientist typically first analyzes a given dataset, and then applies simple preprocessing steps such as missing feature imputation, categorical feature encoding, and feature selection in order to transform the data into a set of features used by the model. They then construct the model itself using a popular machine learning library such as scikit-learn, LightGBM, or Tensorflow.
This workflow is fine for Kaggle-like problems where performance is the sole objective. However, once it becomes time to put this pipeline and model into production, there is a serious concern - robustness to “real-world” data. One such form of robustness comes in the form of resilience to malformed inputs. “Malformed” can mean a variety of things, from a different schema to out of distribution values. Standard preprocessing functions and model packages fail to adequately cover a wide range of input failure cases, making it challenging to guarantee robustness during a production setting.
In this post we’ll explore various types of malformed inputs and how common machine learning packages handle them. The results can be surprising! It turns out that different ML packages actually produce inconsistent behavior when given the same malformed input. More importantly, many of these failures are data-dependent and application-dependent, and therefore any sort of validation logic must take into account custom parameters/thresholds that are not scalable to other settings.
All this means that a data scientist would have to spend a ton of effort in order to handle all possible edge cases themselves! Input validation is a surprisingly complex problem.
Note: to perform all these tests, we used our flagship product RIME. Please contact us if you are interested in a more detailed demo!
The Dataset
We start by using a canonical machine learning dataset: the Titanic survivorship dataset taken from Kaggle. This dataset contains 17 columns, one of which is a “Survived” column, which is used as the label we are attempting to predict. This label is a binary label (all 0s or 1s) and is fairly balanced (38% of data points have a label of 1, the rest have a label of 0). Of the remaining 16 features, 6 are numeric while 10 are string. The training dataset consists of 891 datapoints, while the testing dataset consists of 418 datapoints.
The Models
We train and evaluate a wide selection of model libraries and services on the Titanic dataset. These frameworks can be roughly divided into two categories: popular open source model libraries which we used in local model development, and cloud-hosted AutoML services. Using both a wide range of model libraries as well as including cloud-hosted services allows us to understand if there are subtle differences in package interfaces, and test a variety of preprocessing pipelines. The full collection of tools is described below:
Local Model Packages. For each model package we implement a fairly typical preprocessing and feature engineering pipeline and then experiment with a variety of algorithms. The preprocessing pipeline includes label encoding for the categorical features, and then replacing null values with a numeric placeholder value (-1). The model packages include:
- General purpose tools: scikit-learn (logistic regression, KNN, random forest)
- Tree-based Packages: Catboost, LightGBM, XGBoost
- Deep Learning Frameworks: Tensorflow, PyTorch
Cloud-hosted AutoML Services. For these models we utilized the AutoML capabilities of several cloud model providers. Because the entire model pipeline is done in a blackbox manner within the AutoML service, we do not know exactly what the preprocessing steps for these pipelines included. The AutoML services include:
- Google AutoML
- DataRobot
Results
Below is a table of the results of testing various types of malformed inputs on a collection of models. After that, we dive a bit deeper into the results, analyzing common failure (and success) patterns.
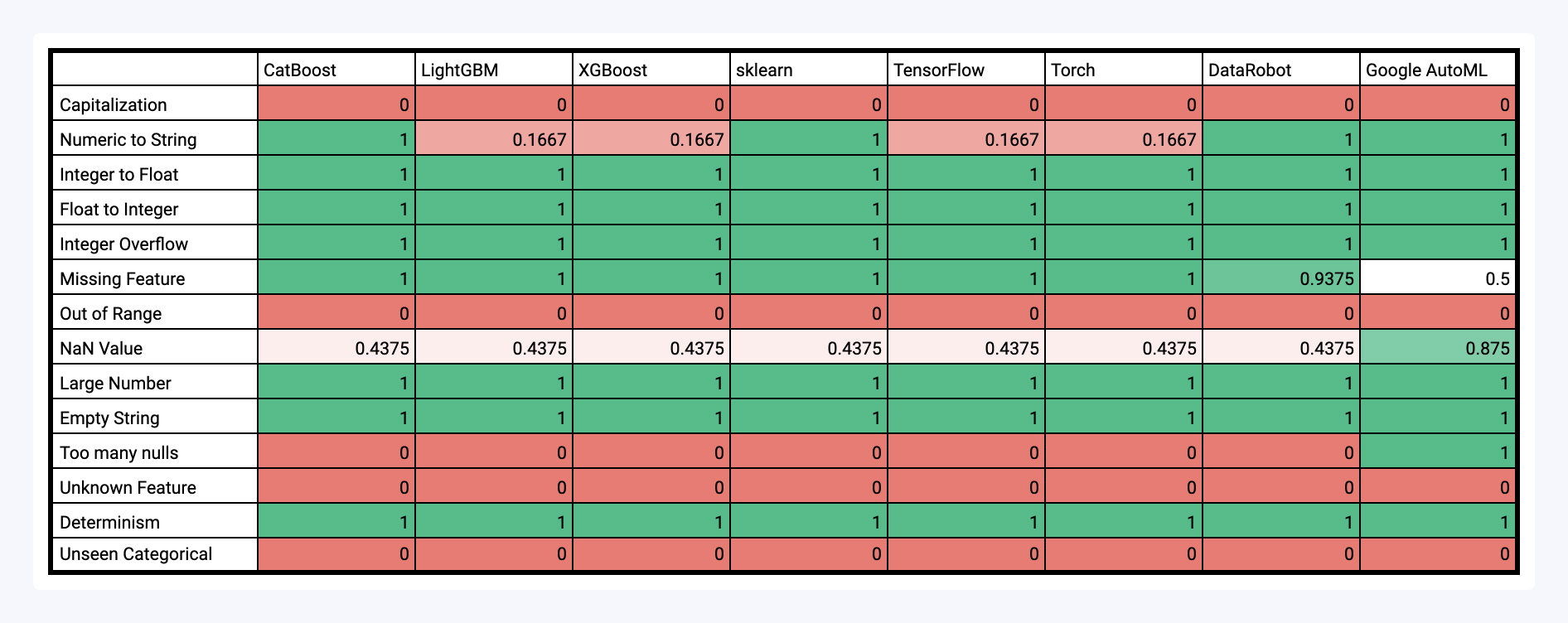
Successful Tests
We did see that the modeling pipelines we evaluated were robust to several types of malformed inputs. These include things like:
- Integer/Float Conversion: are numeric values treated the same regardless of whether they are represented as an integer (e.g. `1`) or a float (e.g. `1.0`)
- Integer Overflow: does there appear to be any type casting going on in the model that causes integer overflow to occur?
- Empty strings: are null values and empty string values treated the same?
While it is relieving to see these, these are also some of the easier edge cases we tested. That brings us to…
Failed Tests
We also observe that all models fail several tests, meaning there are some types of malformed inputs that no models are robust to. These include:
- Unseen Categorical: We expect models, when presented with a categorical value that it has not seen before for a certain feature, to throw an error. None of the model pipelines do.
- Unknown feature: We expect models to throw some type of warning when an extra, previously unseen feature is passed in. None of the model pipelines do.
- Out of Range: We expect models to throw some type of warning when drastically out of range values are passed in (e.g. a value of 1000 for the feature Age in this dataset). None of the model pipelines do.
- Capitalization: We expect models to handle string values the same, regardless of capitalization. None of the model pipelines do.
On deeper analysis, there are key differences between these tests and the tests under common successes: the appropriate thresholds of validity for these tests are very much data-dependent and application-dependent. One can imagine application domains where unseen categorical values are seen very frequently during inference and are inherently handled by the underlying model, so therefore the desired behavior is not to throw an error. But on the other hand, one can imagine domains where unseen categoricals during inference are a huge red flag and a sign of data corruption (e.g. a Month field or a US State field). And this is a key lesson to takeaway from this analysis: because the expected behavior of these tests is more subjective, they are not by default included in most preprocessing steps/package interfaces.
Inconsistent Test Results
Finally, many input validation tests actually yield inconsistent behavior between models/packages. These include:
- Numeric to String: This tests whether a model can handle a string representation of a numeric value. We can see that several models can (e.g. CatBoost, scikit-learn, and the AutoML providers)`, as under the hood they try to do some type conversion, while others do not.
- NaN values: This tests whether a model appropriately handles null values. The expected behavior for this is that when a column has null values in the training dataset, it should be able to make a prediction, whereas if there was no null value in the training data it should throw a warning. Most models accept null values regardless of whether they were present in the training data, leading to the same pass rate (0.4375). However, some, like Google AutoML, do a better job of throwing errors if a null value was passed in for a column that should not be null. This also explains the difference in the Too Many Nulls test.
- Missing Features: This tests how the model deals with inputs that do not contain a certain feature (this is different from the null test). We expect a model to raise a warning if a feature is not passed at all. We can see the locally developed models all raise a warning, while some of the AutoML models are a bit more lax and don’t flag inputs with missing features.
Some of these tests that yield inconsistent behavior between models can also be thought of as subjective (e.g. the proportion of allowable nan values can be thought of as an application-dependent threshold). Yet the fact that different packages actually yield different results in these tests means that the data scientist now has to carefully consider whether the default behavior of a package is consistent or inconsistent with their expected desired behavior. These behavioral inconsistencies further reinforce the need to have rigorous input validation checks, even as the subjective nature of such tests render it challenging for the user to fully implement.
Lesson: Input Validation is Harder than you think
The tests help to showcase the challenges of effectively and efficiently testing data pipelines and machine learning models. Because some input validation failures are inherently data-dependent and application-dependent, they are inherently subjective and require custom logic per dataset/model/feature column. A data scientist writing numeric bounds for a given feature in order to detect out-of-range values cannot use the same numeric bounds for other feature columns, much less other datasets; a threshold of at most 10% nulls within a datapoint may work for one application domain but may be too tight of a bound for noisier datasets. This implies that for a data scientist to effectively cover all the edge cases a model may encounter in production, they must spend a considerable amount of time writing verification logic for every dataset and model.
The fact that this is a crucial step for any individual or company looking to productionize their ML system indicates the need for a horizontal platform that can efficiently and effectively profile and test any given data and model pipeline. Such a platform must have intelligent data profiling capabilities to infer the necessary tests from the data, while also offering the flexibility for users to configure and add their own tests. That is precisely the role that RIME fills.





